
📎 ❮GEOJSON file❯ | INPUT-path.geojson
📎 ❮CSV file❯ | INPUT-queries.csv 📝
📎 ❮CRX file❯ | GPlaces-get.crx ⚙
Open to any Contributions
may the source be with you!
Read this!
You can reach me on Telegram @forthetim6being
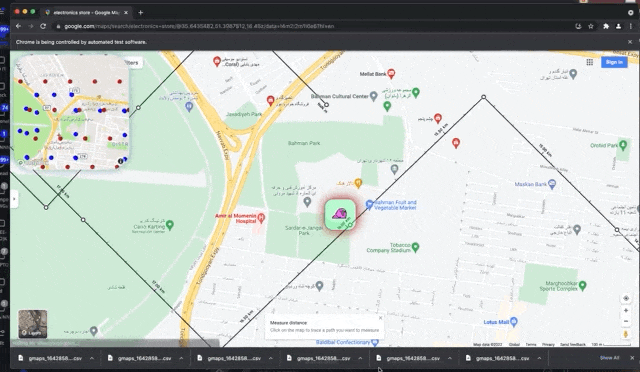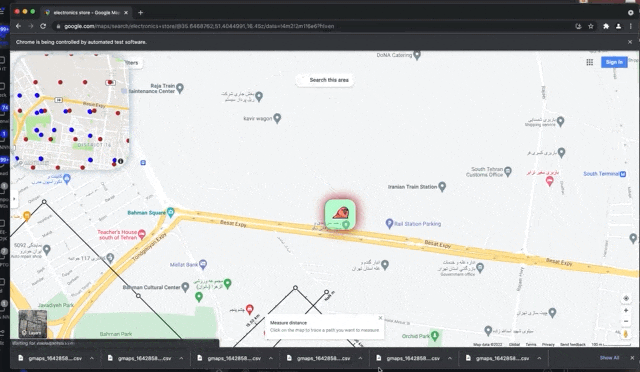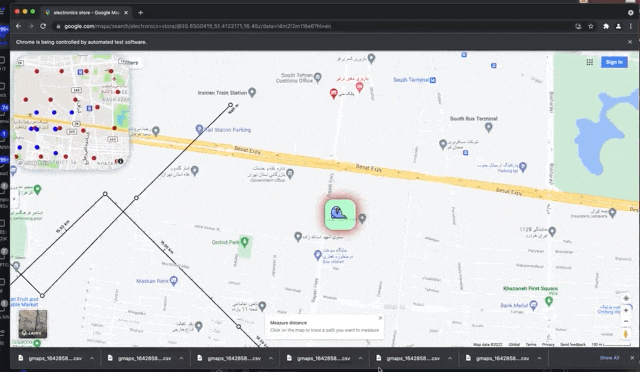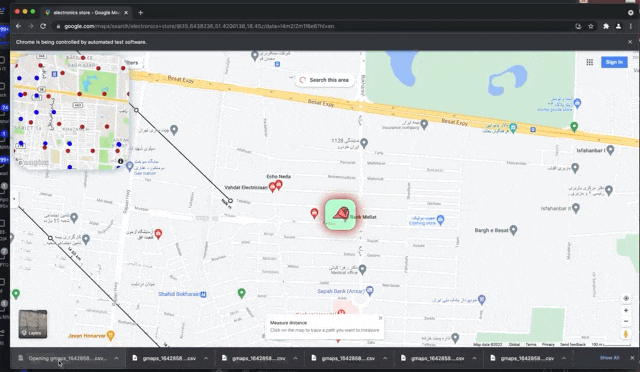
🚶Scraping google places using Selenium Python in a simple approach.
⚡ No need to google maps API
⭐ No need of any scrolling on the google maps sidebar or handling the pagination
🧮 In case of URL redirecting triggered by google maps, It continue the scraping process from the last place it has been scraped.
🪁 Predefined scraping track as a ❮☡ GEOJSON file❯, define the movement path of the scraper on the map.
🧬 Each time the app starts, it reads the customized search queries and map zooms from the ❮CSV input file❯. as there may be more than a single query, It may repeat the track for any query and map zoom once it finished the track.
When your money value become close to zero in the real world outside your country, google APIs may not be in your options as a hobbyist data enthusiast. this project may be beneficial for small projects, looking to a fast and easy way to look around the local places data.
Previous open-source selenium tools have been mostly based on scrolling on the google maps paginated sidebar of places and scrape the data. However, in this project, google places information are extracted from the local storage of the browser directly with using the content scripts of the GPlaces-get extension, as another open-source project on JavaScript. So without the use of any google APIs, map viewport gets moving and moving on the predefined path and extracts the places data as CSV files for every scraped places (default: 100).
pysel-map-scraper get's moving on the map based on the ❮☡ GEOJSON file❯ defining the path (INPUT_path.geojson). It run the procedure of scraping for each of search queries in the CSV input file (INPUT-queries.csv), And restart the path once each query finished. The app triggers "search this area" button every time gets to a new viewport. GPlaces-get is writing all the data on CSV files and exporting them automatically, whenever it stores 100 new places (and also you may customize this).
anytime you run the app, it uses the stored logs and gets able to continue the process from the last location&query it has been scraped.
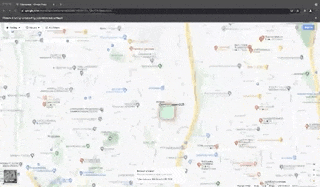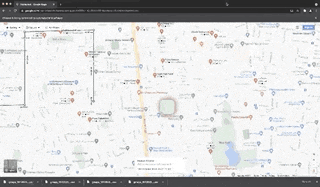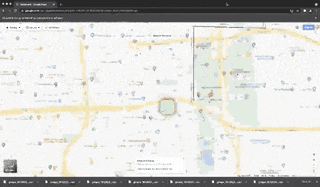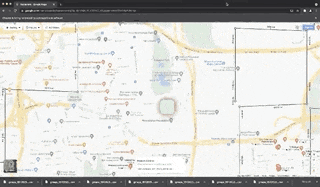
Scraped fields for each place:
| UUID | Created_at | Query | Full address | Local Name | Local full address | Latitude & Longitude | Categories | Reviews |
|---|---|---|---|---|---|---|---|---|
| Rating | URL | Domain | Thumbnail | Addr1 | Addr2 | Addr3 | District | Timezone |
-
Clone this repository.
-
Put the 📎
❮GPlaces-get.crx❯in . / pysel-map-scraper-SOC / [move to here] Either download the GPlaces-get.crx or clone it's repository and export it to CRX using google chrome extensions developer tools (or other applicable tools). -
Donwload the latest chromedriver (which is also open-source) for your operating system from the link below: https://browsers.chromedriver.chromium.org It is an open source tool for automated testing of webapps across many browsers. It provides capabilities for navigating to web pages, user input, JavaScript execution, and more. ChromeDriver is a standalone server that implements the W3C WebDriver standard, and is available for Chrome on Android and Chrome on Desktop (Mac, Linux, Windows and ChromeOS).
-
Complete the INPUT_queries CSV files. It has two columns (query, zoom). each row will be scraped on the map seperately. feel free to add rows as much as you want.
-
Go to terminal and open your source directory. then use the following code to run the code:
sudo python3 main.py