About • Training results • Installation • How To Use • Credits • License
This repository contains a implementation of Deep Speech 2 Automatic Speech Recognition model made form scratch with PyTorch. Deep Speech 2 is an end-to-end deep learning model designed for Automatic Speech Recognition (ASR). It uses a combination of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to process raw audio features (e.g., spectrograms) and predict corresponding text transcriptions. The model is based on Baidu DeepSpeech2 paper and follows this architecture:
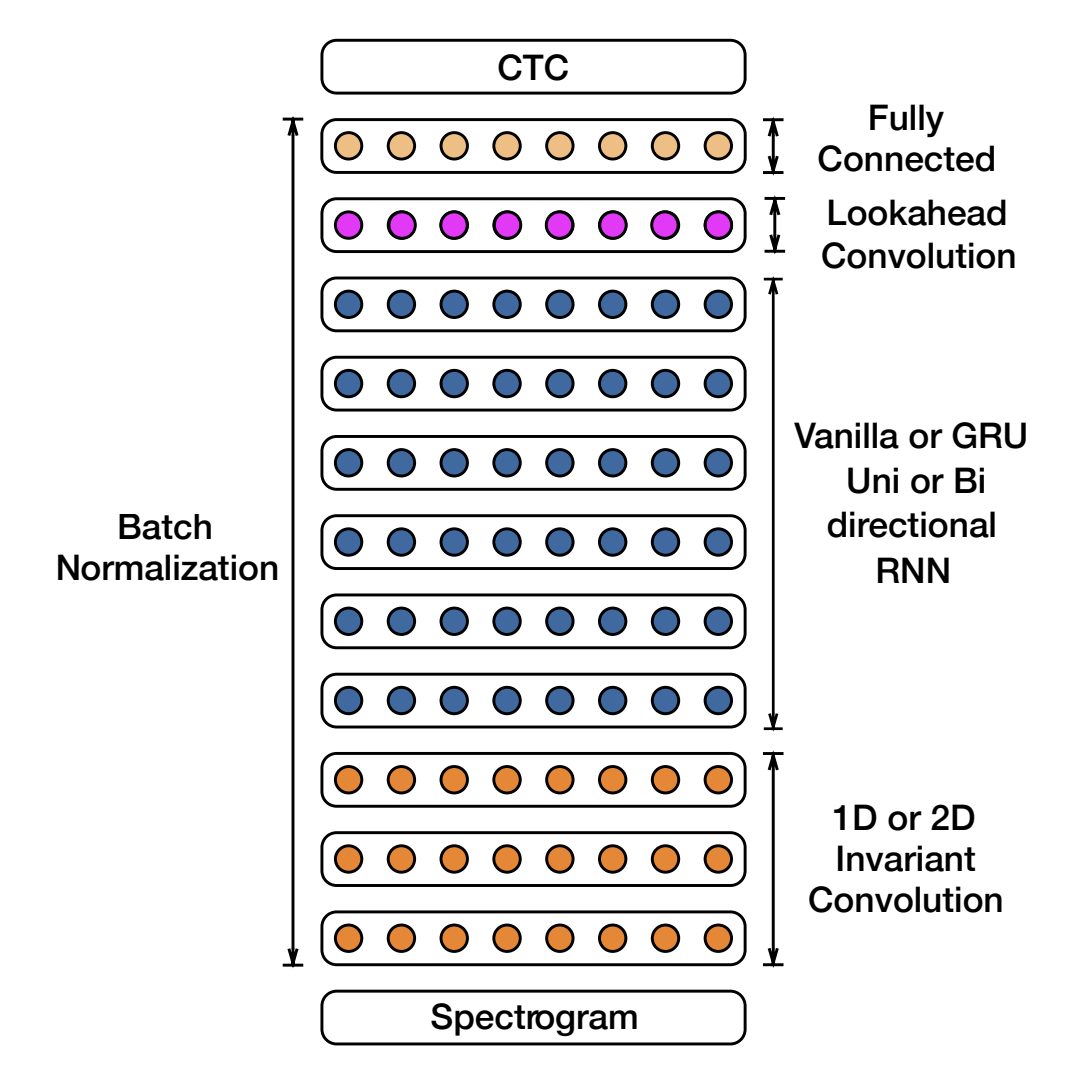
Tables with model's outputs during training and evaluation can be viewed in report. Overall model achieved WER of 0.44 and CER of 0.12 on average during evaluation
Follow these steps to install the project:
-
(Optional) Create and activate new environment using
condaorvenv(+pyenv).a.
condaversion:# create env conda create -n project_env python=PYTHON_VERSION # activate env conda activate project_env
b.
venv(+pyenv) version:# create env ~/.pyenv/versions/PYTHON_VERSION/bin/python3 -m venv project_env # alternatively, using default python version python3 -m venv project_env # activate env source project_env
-
Install all required packages
pip install -r requirements.txt
-
Install
pre-commit:pre-commit install
To train a model, run the following command:
python3 train.py -cn=CONFIG_NAME HYDRA_CONFIG_ARGUMENTSWhere CONFIG_NAME is a config from src/configs and HYDRA_CONFIG_ARGUMENTS are optional arguments.
To run inference (evaluate the model or save predictions):
python3 inference.py HYDRA_CONFIG_ARGUMENTSThis repository is based on a PyTorch Project Template.