-
Notifications
You must be signed in to change notification settings - Fork 1.3k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
* add photopen * update photopen.md * fix photopen_model.py * fix the ci problem Co-authored-by: qingqing01 <[email protected]>
- Loading branch information
1 parent
283c891
commit 87537ad
Showing
32 changed files
with
1,332 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,48 @@ | ||
| import paddle | ||
| import os | ||
| import sys | ||
|
|
||
| sys.path.insert(0, os.getcwd()) | ||
| from ppgan.apps import PhotoPenPredictor | ||
| import argparse | ||
| from ppgan.utils.config import get_config | ||
|
|
||
| if __name__ == "__main__": | ||
| parser = argparse.ArgumentParser() | ||
|
|
||
| parser.add_argument("--semantic_label_path", | ||
| type=str, | ||
| default=None, | ||
| help="path to input semantic label") | ||
|
|
||
| parser.add_argument("--output_path", | ||
| type=str, | ||
| default=None, | ||
| help="path to output image dir") | ||
|
|
||
| parser.add_argument("--weight_path", | ||
| type=str, | ||
| default=None, | ||
| help="path to model weight") | ||
|
|
||
| parser.add_argument("--config-file", | ||
| type=str, | ||
| default=None, | ||
| help="path to yaml file") | ||
|
|
||
| parser.add_argument("--cpu", | ||
| dest="cpu", | ||
| action="store_true", | ||
| help="cpu mode.") | ||
|
|
||
| args = parser.parse_args() | ||
|
|
||
| if args.cpu: | ||
| paddle.set_device('cpu') | ||
|
|
||
| cfg = get_config(args.config_file) | ||
| predictor = PhotoPenPredictor(output_path=args.output_path, | ||
| weight_path=args.weight_path, | ||
| gen_cfg=cfg.predict) | ||
| predictor.run(semantic_label_path=args.semantic_label_path) | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,96 @@ | ||
| total_iters: 1 | ||
| output_dir: output_dir | ||
| checkpoints_dir: checkpoints | ||
|
|
||
| model: | ||
| name: PhotoPenModel | ||
| generator: | ||
| name: SPADEGenerator | ||
| ngf: 24 | ||
| num_upsampling_layers: normal | ||
| crop_size: 256 | ||
| aspect_ratio: 1.0 | ||
| norm_G: spectralspadebatch3x3 | ||
| semantic_nc: 14 | ||
| use_vae: False | ||
| nef: 16 | ||
| discriminator: | ||
| name: MultiscaleDiscriminator | ||
| ndf: 128 | ||
| num_D: 4 | ||
| crop_size: 256 | ||
| label_nc: 12 | ||
| output_nc: 3 | ||
| contain_dontcare_label: True | ||
| no_instance: False | ||
| n_layers_D: 6 | ||
| criterion: | ||
| name: PhotoPenPerceptualLoss | ||
| crop_size: 224 | ||
| lambda_vgg: 1.6 | ||
| label_nc: 12 | ||
| contain_dontcare_label: True | ||
| batchSize: 1 | ||
| crop_size: 256 | ||
| lambda_feat: 10.0 | ||
|
|
||
| dataset: | ||
| train: | ||
| name: PhotoPenDataset | ||
| content_root: test/coco_stuff | ||
| load_size: 286 | ||
| crop_size: 256 | ||
| num_workers: 0 | ||
| batch_size: 1 | ||
| test: | ||
| name: PhotoPenDataset_test | ||
| content_root: test/coco_stuff | ||
| load_size: 286 | ||
| crop_size: 256 | ||
| num_workers: 0 | ||
| batch_size: 1 | ||
|
|
||
| lr_scheduler: # abundoned | ||
| name: LinearDecay | ||
| learning_rate: 0.0001 | ||
| start_epoch: 99999 | ||
| decay_epochs: 99999 | ||
| # will get from real dataset | ||
| iters_per_epoch: 1 | ||
|
|
||
| optimizer: | ||
| lr: 0.0001 | ||
| optimG: | ||
| name: Adam | ||
| net_names: | ||
| - net_gen | ||
| beta1: 0.9 | ||
| beta2: 0.999 | ||
| optimD: | ||
| name: Adam | ||
| net_names: | ||
| - net_des | ||
| beta1: 0.9 | ||
| beta2: 0.999 | ||
|
|
||
| log_config: | ||
| interval: 1 | ||
| visiual_interval: 1 | ||
|
|
||
| snapshot_config: | ||
| interval: 1 | ||
|
|
||
| predict: | ||
| name: SPADEGenerator | ||
| ngf: 24 | ||
| num_upsampling_layers: normal | ||
| crop_size: 256 | ||
| aspect_ratio: 1.0 | ||
| norm_G: spectralspadebatch3x3 | ||
| semantic_nc: 14 | ||
| use_vae: False | ||
| nef: 16 | ||
| contain_dontcare_label: True | ||
| label_nc: 12 | ||
| batchSize: 1 | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,104 @@ | ||
| # GauGAN(加SimAM注意力的改进版) | ||
|
|
||
| ## 1.简介: | ||
|
|
||
| 本应用的模型出自论文《Semantic Image Synthesis with Spatially-Adaptive Normalization》,是一个像素风格迁移网络 Pix2PixHD,能够根据输入的语义分割标签生成照片风格的图片。为了解决模型归一化层导致标签语义信息丢失的问题,论文作者向 Pix2PixHD 的生成器网络中添加了 SPADE(Spatially-Adaptive Normalization)空间自适应归一化模块,通过两个卷积层保留了归一化时训练的缩放与偏置参数的空间维度,以增强生成图片的质量。 | ||
|
|
||
| 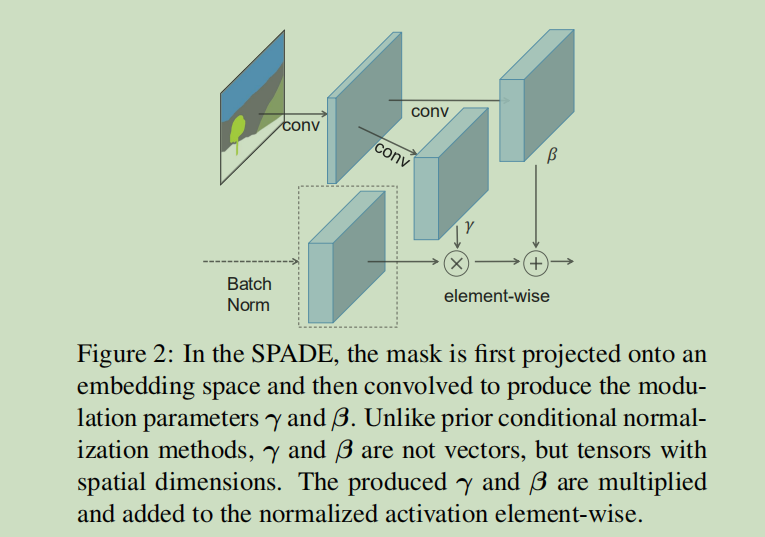 | ||
|
|
||
| 此模型在 GauGAN 的 SPADE 模块上添加了无参的 SimAM 注意力模块,增强了生成图片的立体质感。 | ||
|
|
||
|  | ||
|
|
||
| ## 2.快速体验 | ||
|
|
||
| 预训练模型可以从如下地址下载: (https://paddlegan.bj.bcebos.com/models/photopen.pdparams) | ||
|
|
||
| 输入一张png格式的语义标签图片给模型,输出一张按标签语义生成的照片风格的图片。预测代码如下: | ||
|
|
||
| ``` | ||
| python applications/tools/photopen.py \ | ||
| --semantic_label_path test/sem.png \ | ||
| --weight_path test/n_g.pdparams \ | ||
| --output_path test/pic.jpg \ | ||
| --config-file configs/photopen.yaml | ||
| ``` | ||
|
|
||
| **参数说明:** | ||
| * semantic_label_path:输入的语义标签路径,为png图片文件 | ||
| * weight_path:训练完成的模型权重存储路径,为 statedict 格式(.pdparams)的 Paddle 模型行权重文件 | ||
| * output_path:预测生成图片的存储路径 | ||
| * config-file:存储参数设定的yaml文件存储路径,与训练过程使用同一个yaml文件,预测参数由 predict 下字段设定 | ||
|
|
||
| ## 3.训练 | ||
|
|
||
| **数据准备:** | ||
|
|
||
| 数据集目录结构如下: | ||
|
|
||
| ``` | ||
| └─coco_stuff | ||
| ├─train_img | ||
| └─train_inst | ||
| ``` | ||
|
|
||
| coco_stuff 是数据集根目录可任意改变,其下的 train_img 子目录存放训练用的风景图片(一般jpg格式),train_inst 子目录下存放与风景图片文件名一一对应、尺寸相同的语义标签图片(一般png格式)。 | ||
|
|
||
| ### 3.1 gpu 单卡训练 | ||
|
|
||
| `python -u tools/main.py --config-file configs/photopen.yaml` | ||
|
|
||
| * config-file:训练使用的超参设置 yamal 文件的存储路径 | ||
|
|
||
| ### 3.2 gpu 多卡训练 | ||
|
|
||
| ``` | ||
| !python -m paddle.distributed.launch \ | ||
| tools/main.py \ | ||
| --config-file configs/photopen.yaml \ | ||
| -o model.generator.norm_G=spectralspadesyncbatch3x3 \ | ||
| model.batchSize=4 \ | ||
| dataset.train.batch_size=4 | ||
| ``` | ||
|
|
||
| * config-file:训练使用的超参设置 yamal 文件的存储路径 | ||
| * model.generator.norm_G:设置使用 syncbatch 归一化,使多个 GPU 中的数据一起进行归一化 | ||
| * model.batchSize:设置模型的 batch size,一般为 GPU 个数的整倍数 | ||
| * dataset.train.batch_size:设置数据读取的 batch size,要和模型的 batch size 一致 | ||
|
|
||
| ### 3.3 继续训练 | ||
|
|
||
| `python -u tools/main.py --config-file configs/photopen.yaml --resume output_dir\photopen-2021-09-30-15-59\iter_3_checkpoint.pdparams` | ||
|
|
||
| * config-file:训练使用的超参设置 yamal 文件的存储路径 | ||
| * resume:指定读取的 checkpoint 路径 | ||
|
|
||
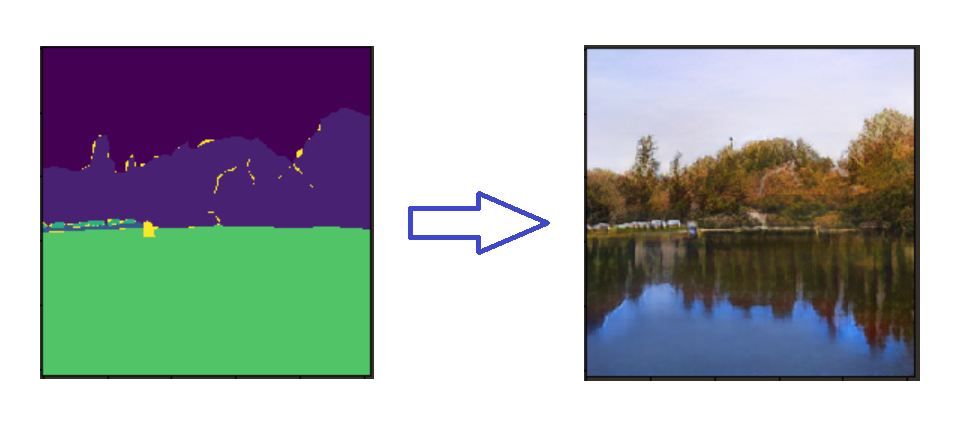
| ## 4.模型效果展示 | ||
|
|
||
|  | ||
|
|
||
| ## 5.参考 | ||
|
|
||
| ``` | ||
| @inproceedings{park2019SPADE, | ||
| title={Semantic Image Synthesis with Spatially-Adaptive Normalization}, | ||
| author={Park, Taesung and Liu, Ming-Yu and Wang, Ting-Chun and Zhu, Jun-Yan}, | ||
| booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, | ||
| year={2019} | ||
| } | ||
| @InProceedings{pmlr-v139-yang21o, | ||
| title = {SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks}, | ||
| author = {Yang, Lingxiao and Zhang, Ru-Yuan and Li, Lida and Xie, Xiaohua}, | ||
| booktitle = {Proceedings of the 38th International Conference on Machine Learning}, | ||
| pages = {11863--11874}, | ||
| year = {2021}, | ||
| editor = {Meila, Marina and Zhang, Tong}, | ||
| volume = {139}, | ||
| series = {Proceedings of Machine Learning Research}, | ||
| month = {18--24 Jul}, | ||
| publisher = {PMLR}, | ||
| pdf = {http://proceedings.mlr.press/v139/yang21o/yang21o.pdf}, | ||
| url = {http://proceedings.mlr.press/v139/yang21o.html} | ||
| } | ||
| ``` |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,76 @@ | ||
| # Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| from PIL import Image, ImageOps | ||
| import cv2 | ||
| import numpy as np | ||
| import os | ||
|
|
||
| import paddle | ||
|
|
||
| from .base_predictor import BasePredictor | ||
| from ppgan.models.generators import SPADEGenerator | ||
| from ppgan.utils.photopen import data_onehot_pro | ||
| from ..utils.filesystem import load | ||
|
|
||
|
|
||
| class PhotoPenPredictor(BasePredictor): | ||
| def __init__(self, | ||
| output_path, | ||
| weight_path, | ||
| gen_cfg): | ||
|
|
||
| # 初始化模型 | ||
| gen = SPADEGenerator( | ||
| gen_cfg.ngf, | ||
| gen_cfg.num_upsampling_layers, | ||
| gen_cfg.crop_size, | ||
| gen_cfg.aspect_ratio, | ||
| gen_cfg.norm_G, | ||
| gen_cfg.semantic_nc, | ||
| gen_cfg.use_vae, | ||
| gen_cfg.nef, | ||
| ) | ||
| gen.eval() | ||
| para = load(weight_path) | ||
| if 'net_gen' in para: | ||
| gen.set_state_dict(para['net_gen']) | ||
| else: | ||
| gen.set_state_dict(para) | ||
|
|
||
| self.gen = gen | ||
| self.output_path = output_path | ||
| self.gen_cfg = gen_cfg | ||
|
|
||
|
|
||
| def run(self, semantic_label_path): | ||
| sem = Image.open(semantic_label_path) | ||
| sem = sem.resize((self.gen_cfg.crop_size, self.gen_cfg.crop_size), Image.NEAREST) | ||
| sem = np.array(sem).astype('float32') | ||
| sem = paddle.to_tensor(sem) | ||
| sem = sem.reshape([1, 1, self.gen_cfg.crop_size, self.gen_cfg.crop_size]) | ||
|
|
||
| one_hot = data_onehot_pro(sem, self.gen_cfg) | ||
| predicted = self.gen(one_hot) | ||
| pic = predicted.numpy()[0].reshape((3, 256, 256)).transpose((1,2,0)) | ||
| pic = ((pic + 1.) / 2. * 255).astype('uint8') | ||
|
|
||
| pic = cv2.cvtColor(pic,cv2.COLOR_BGR2RGB) | ||
| path, _ = os.path.split(self.output_path) | ||
| if not os.path.exists(path): | ||
| os.mkdir(path) | ||
| cv2.imwrite(self.output_path, pic) | ||
|
|
||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.