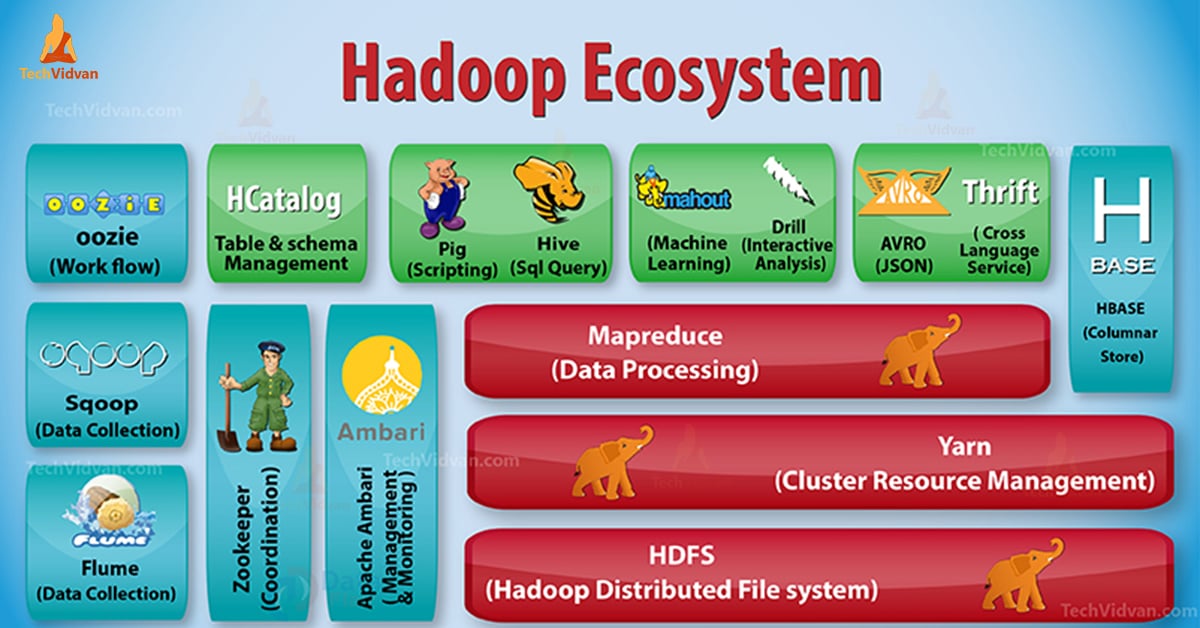
- Hadoop Common
- Hadoop Distributed File System (HDFS)
- Hadoop YARN
- Hadoop MapReduce
Hadoop Distributed File System (based on Google File System, GFS)
- Serves as the distributed file system for most tools in the Hadoop ecosystem
- Scalability for large data sets
- Reliability to cope with hardware failures
HDFS good for
- Large files
Not good for
- Lots of small files
- Low latency access (because Disk I/O)
Master/Slave design
- Master node
- Single NameNode for managing metadata
- Slave node
- Multiple DataNode for storing data
- Other
- Secondary NameNode as a backup

NameNode
- keeps the metadata, the name, location and directory
DataNode
- provides storage for blocks of data
Replication of Blocks for fault tolerance
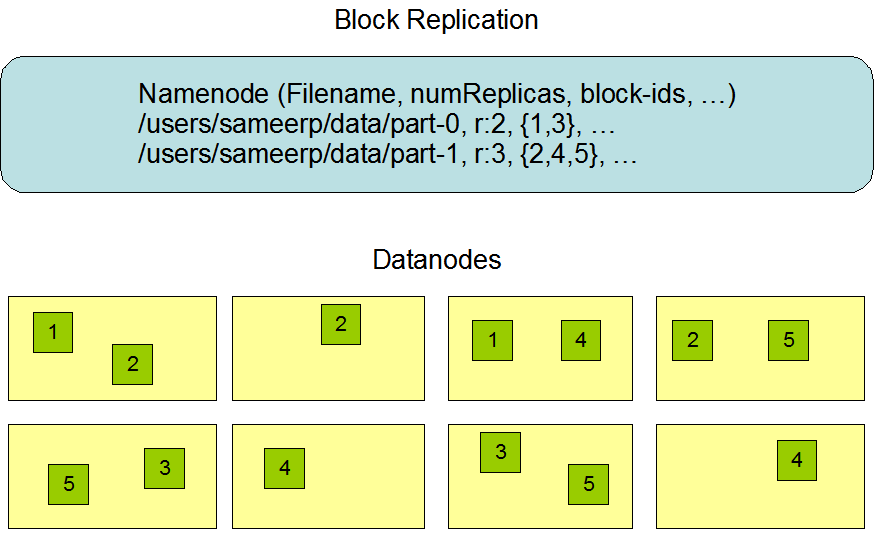

HDFS files are divided into blocks
- It's the basic unit of read/write
- Default block size is 128MB
- Hence makes HDFS good for large files, not good for small files
HDFS blocks are replicated multiple times
- One block stored at multiple location, also at different racks (usually 3 times)
- This makes HDFS storage fault tolerance and faster to read
Data processing model designed to process large amounts of data in a distributed/parallel computing environment
When large data comes in, the data is divided into blocks of a certain size and a Map Task and a Reduce Task are performed for each block.

Simple programming paradigm for the Hadoop ecosystem
Traditional parallel programming requires expertise of different parallel programming paradigms
The Map Task and the Reduce Task use the Key-Value structure for input and output. Map refers to an operation of grouping processed data in the form of (Key, Value)
- The Map returns data in the form of a Key, Value in the form of a List.
- The Reduce removes and merges data with duplicate key values from data processed with Map, and extracts the desired data.