|
| 1 | +# SECOND for KITTI/NuScenes object detection |
| 2 | +SECOND detector. |
| 3 | + |
| 4 | +ONLY support python 3.6+, pytorch 1.0.0+. Tested in Ubuntu 16.04/18.04/Windows 10. |
| 5 | + |
| 6 | +If you want to train nuscenes dataset, see [this](NUSCENES-GUIDE.md). |
| 7 | + |
| 8 | +## News |
| 9 | + |
| 10 | +2019-4-1: SECOND V1.6.0alpha released: New Data API, [NuScenes](https://www.nuscenes.org) support, [PointPillars](https://github.com/nutonomy/second.pytorch) support, fp16 and multi-gpu support. |
| 11 | + |
| 12 | +2019-3-21: SECOND V1.5.1 (minor improvement and bug fix) released! |
| 13 | + |
| 14 | +2019-1-20: SECOND V1.5 released! Sparse convolution-based network. |
| 15 | + |
| 16 | +See [release notes](RELEASE.md) for more details. |
| 17 | + |
| 18 | +_WARNING_: you should rerun info generation after every code update. |
| 19 | + |
| 20 | +### Performance in KITTI validation set (50/50 split) |
| 21 | + |
| 22 | +```car.fhd.config``` + 160 epochs (25 fps in 1080Ti): |
| 23 | + |
| 24 | +``` |
| 25 | +Car [email protected], 0.70, 0.70: |
| 26 | +bbox AP:90.77, 89.50, 80.80 |
| 27 | +bev AP:90.28, 87.73, 79.67 |
| 28 | +3d AP:88.84, 78.43, 76.88 |
| 29 | +``` |
| 30 | + |
| 31 | +```car.fhd.config``` + 50 epochs + super converge (6.5 hours) + (25 fps in 1080Ti): |
| 32 | + |
| 33 | +``` |
| 34 | +Car [email protected], 0.70, 0.70: |
| 35 | +bbox AP:90.78, 89.59, 88.42 |
| 36 | +bev AP:90.12, 87.87, 86.77 |
| 37 | +3d AP:88.62, 78.31, 76.62 |
| 38 | +``` |
| 39 | + |
| 40 | +```car.fhd.onestage.config``` + 50 epochs + super converge (6.5 hours) + (25 fps in 1080Ti): |
| 41 | + |
| 42 | +``` |
| 43 | +Car [email protected], 0.70, 0.70: |
| 44 | +bbox AP:97.65, 89.59, 88.72 |
| 45 | +bev AP:90.38, 88.20, 86.98 |
| 46 | +3d AP:89.16, 78.78, 77.41 |
| 47 | +``` |
| 48 | + |
| 49 | +### Performance in NuScenes validation set (NuScenes mini train set) |
| 50 | + |
| 51 | +``` |
| 52 | +car Nusc dist [email protected], 1.0, 2.0, 4.0 |
| 53 | +62.80, 73.30, 76.85, 78.87 |
| 54 | +pedestrian Nusc dist [email protected], 1.0, 2.0, 4.0 |
| 55 | +61.09, 62.20, 63.66, 65.89 |
| 56 | +``` |
| 57 | + |
| 58 | +## Install |
| 59 | + |
| 60 | +### 1. Clone code |
| 61 | + |
| 62 | +```bash |
| 63 | +git clone https://github.com/traveller59/second.pytorch.git |
| 64 | +cd ./second.pytorch/second |
| 65 | +``` |
| 66 | + |
| 67 | +### 2. Install dependence python packages |
| 68 | + |
| 69 | +It is recommend to use Anaconda package manager. |
| 70 | + |
| 71 | +```bash |
| 72 | +conda install scikit-image scipy numba pillow matplotlib |
| 73 | +``` |
| 74 | + |
| 75 | +```bash |
| 76 | +pip install fire tensorboardX protobuf opencv-python |
| 77 | +``` |
| 78 | + |
| 79 | +If you don't have Anaconda: |
| 80 | + |
| 81 | +```bash |
| 82 | +pip install numba scikit-image scipy pillow |
| 83 | +``` |
| 84 | + |
| 85 | +Follow instructions in [spconv](https://github.com/traveller59/spconv) to install spconv. |
| 86 | + |
| 87 | +If you want to train with fp16 mixed precision (train faster in RTX series, Titan V/RTX and Tesla V100, but I only have 1080Ti), you need to install [apex](https://github.com/NVIDIA/apex). |
| 88 | + |
| 89 | +If you want to use NuScenes dataset, you need to install [nuscenes-devkit](https://github.com/nutonomy/nuscenes-devkit), I recommend to copy nuscenes in python-sdk to second/.. folder (equalivent to add it to PYTHONPATH) and manually install its dependencies, use pip to install devkit will install many fixed-version library. |
| 90 | + |
| 91 | +### 3. Setup cuda for numba (will be removed in 1.6.0 release) |
| 92 | + |
| 93 | +you need to add following environment variable for numba.cuda, you can add them to ~/.bashrc: |
| 94 | + |
| 95 | +```bash |
| 96 | +export NUMBAPRO_CUDA_DRIVER=/usr/lib/x86_64-linux-gnu/libcuda.so |
| 97 | +export NUMBAPRO_NVVM=/usr/local/cuda/nvvm/lib64/libnvvm.so |
| 98 | +export NUMBAPRO_LIBDEVICE=/usr/local/cuda/nvvm/libdevice |
| 99 | +``` |
| 100 | + |
| 101 | +### 4. add second.pytorch/ to PYTHONPATH |
| 102 | + |
| 103 | +## Prepare dataset |
| 104 | + |
| 105 | +* KITTI Dataset preparation |
| 106 | + |
| 107 | +Download KITTI dataset and create some directories first: |
| 108 | + |
| 109 | +```plain |
| 110 | +└── KITTI_DATASET_ROOT |
| 111 | + ├── training <-- 7481 train data |
| 112 | + | ├── image_2 <-- for visualization |
| 113 | + | ├── calib |
| 114 | + | ├── label_2 |
| 115 | + | ├── velodyne |
| 116 | + | └── velodyne_reduced <-- empty directory |
| 117 | + └── testing <-- 7580 test data |
| 118 | + ├── image_2 <-- for visualization |
| 119 | + ├── calib |
| 120 | + ├── velodyne |
| 121 | + └── velodyne_reduced <-- empty directory |
| 122 | +``` |
| 123 | + |
| 124 | +Then run |
| 125 | +```bash |
| 126 | +python create_data.py kitti_data_prep --data_path=KITTI_DATASET_ROOT |
| 127 | +``` |
| 128 | + |
| 129 | +* [NuScenes](https://www.nuscenes.org) Dataset preparation |
| 130 | + |
| 131 | +Download NuScenes dataset: |
| 132 | +```plain |
| 133 | +└── NUSCENES_TRAINVAL_DATASET_ROOT |
| 134 | + ├── samples <-- key frames |
| 135 | + ├── sweeps <-- frames without annotation |
| 136 | + ├── maps <-- unused |
| 137 | + └── v1.0-trainval <-- metadata and annotations |
| 138 | +└── NUSCENES_TEST_DATASET_ROOT |
| 139 | + ├── samples <-- key frames |
| 140 | + ├── sweeps <-- frames without annotation |
| 141 | + ├── maps <-- unused |
| 142 | + └── v1.0-test <-- metadata |
| 143 | +``` |
| 144 | + |
| 145 | +Then run |
| 146 | +```bash |
| 147 | +python create_data.py nuscenes_data_prep --data_path=NUSCENES_TRAINVAL_DATASET_ROOT --version="v1.0-trainval" --max_sweeps=10 |
| 148 | +python create_data.py nuscenes_data_prep --data_path=NUSCENES_TEST_DATASET_ROOT --version="v1.0-test" --max_sweeps=10 |
| 149 | +``` |
| 150 | + |
| 151 | +* Modify config file |
| 152 | + |
| 153 | +There is some path need to be configured in config file: |
| 154 | + |
| 155 | +```bash |
| 156 | +train_input_reader: { |
| 157 | + ... |
| 158 | + database_sampler { |
| 159 | + database_info_path: "/path/to/dataset_dbinfos_train.pkl" |
| 160 | + ... |
| 161 | + } |
| 162 | + dataset: { |
| 163 | + dataset_class_name: "DATASET_NAME" |
| 164 | + kitti_info_path: "/path/to/dataset_infos_train.pkl" |
| 165 | + kitti_root_path: "DATASET_ROOT" |
| 166 | + } |
| 167 | +} |
| 168 | +... |
| 169 | +eval_input_reader: { |
| 170 | + ... |
| 171 | + dataset: { |
| 172 | + dataset_class_name: "DATASET_NAME" |
| 173 | + kitti_info_path: "/path/to/dataset_infos_val.pkl" |
| 174 | + kitti_root_path: "DATASET_ROOT" |
| 175 | + } |
| 176 | +} |
| 177 | +``` |
| 178 | + |
| 179 | +## Usage |
| 180 | + |
| 181 | +### train |
| 182 | + |
| 183 | +I recommend to use script.py to train and eval. see script.py for more details. |
| 184 | + |
| 185 | +#### train with single GPU |
| 186 | + |
| 187 | +```bash |
| 188 | +python ./pytorch/train.py train --config_path=./configs/car.fhd.config --model_dir=/path/to/model_dir |
| 189 | +``` |
| 190 | + |
| 191 | +#### train with multiple GPU (need test, I only have one GPU) |
| 192 | + |
| 193 | +Assume you have 4 GPUs and want to train with 3 GPUs: |
| 194 | + |
| 195 | +```bash |
| 196 | +CUDA_VISIBLE_DEVICES=0,1,3 python ./pytorch/train.py train --config_path=./configs/car.fhd.config --model_dir=/path/to/model_dir --multi_gpu=True |
| 197 | +``` |
| 198 | + |
| 199 | +Note: The batch_size and num_workers in config file is per-GPU, if you use multi-gpu, they will be multiplied by number of GPUs. Don't modify them manually. |
| 200 | + |
| 201 | +You need to modify total step in config file. For example, 50 epochs = 15500 steps for car.lite.config and single GPU, if you use 4 GPUs, you need to divide ```steps``` and ```steps_per_eval``` by 4. |
| 202 | + |
| 203 | +#### train with fp16 (mixed precision) |
| 204 | + |
| 205 | +Modify config file, set enable_mixed_precision to true. |
| 206 | + |
| 207 | +* Make sure "/path/to/model_dir" doesn't exist if you want to train new model. A new directory will be created if the model_dir doesn't exist, otherwise will read checkpoints in it. |
| 208 | + |
| 209 | +* training process use batchsize=6 as default for 1080Ti, you need to reduce batchsize if your GPU has less memory. |
| 210 | + |
| 211 | +* Currently only support single GPU training, but train a model only needs 20 hours (165 epoch) in a single 1080Ti and only needs 50 epoch to reach 78.3 AP with super converge in car moderate 3D in Kitti validation dateset. |
| 212 | + |
| 213 | +### evaluate |
| 214 | + |
| 215 | +```bash |
| 216 | +python ./pytorch/train.py evaluate --config_path=./configs/car.fhd.config --model_dir=/path/to/model_dir --measure_time=True --batch_size=1 |
| 217 | +``` |
| 218 | + |
| 219 | +* detection result will saved as a result.pkl file in model_dir/eval_results/step_xxx or save as official KITTI label format if you use --pickle_result=False. |
| 220 | + |
| 221 | +### pretrained model |
| 222 | + |
| 223 | +You can download pretrained models in [google drive](https://drive.google.com/open?id=1YOpgRkBgmSAJwMknoXmitEArNitZz63C). The ```car_fhd``` model is corresponding to car.fhd.config. |
| 224 | + |
| 225 | +Note that this pretrained model is trained before a bug of sparse convolution fixed, so the eval result may slightly worse. |
| 226 | + |
| 227 | +## Docker (Deprecated. I can't push docker due to network problem.) |
| 228 | + |
| 229 | +You can use a prebuilt docker for testing: |
| 230 | +``` |
| 231 | +docker pull scrin/second-pytorch |
| 232 | +``` |
| 233 | +Then run: |
| 234 | +``` |
| 235 | +nvidia-docker run -it --rm -v /media/yy/960evo/datasets/:/root/data -v $HOME/pretrained_models:/root/model --ipc=host second-pytorch:latest |
| 236 | +python ./pytorch/train.py evaluate --config_path=./configs/car.config --model_dir=/root/model/car |
| 237 | +``` |
| 238 | + |
| 239 | +## Try Kitti Viewer Web |
| 240 | + |
| 241 | +### Major step |
| 242 | + |
| 243 | +1. run ```python ./kittiviewer/backend/main.py main --port=xxxx``` in your server/local. |
| 244 | + |
| 245 | +2. run ```cd ./kittiviewer/frontend && python -m http.server``` to launch a local web server. |
| 246 | + |
| 247 | +3. open your browser and enter your frontend url (e.g. http://127.0.0.1:8000, default]). |
| 248 | + |
| 249 | +4. input backend url (e.g. http://127.0.0.1:16666) |
| 250 | + |
| 251 | +5. input root path, info path and det path (optional) |
| 252 | + |
| 253 | +6. click load, loadDet (optional), input image index in center bottom of screen and press Enter. |
| 254 | + |
| 255 | +### Inference step |
| 256 | + |
| 257 | +Firstly the load button must be clicked and load successfully. |
| 258 | + |
| 259 | +1. input checkpointPath and configPath. |
| 260 | + |
| 261 | +2. click buildNet. |
| 262 | + |
| 263 | +3. click inference. |
| 264 | + |
| 265 | + |
| 266 | + |
| 267 | + |
| 268 | + |
| 269 | +## Try Kitti Viewer (Deprecated) |
| 270 | + |
| 271 | +You should use kitti viewer based on pyqt and pyqtgraph to check data before training. |
| 272 | + |
| 273 | +run ```python ./kittiviewer/viewer.py```, check following picture to use kitti viewer: |
| 274 | +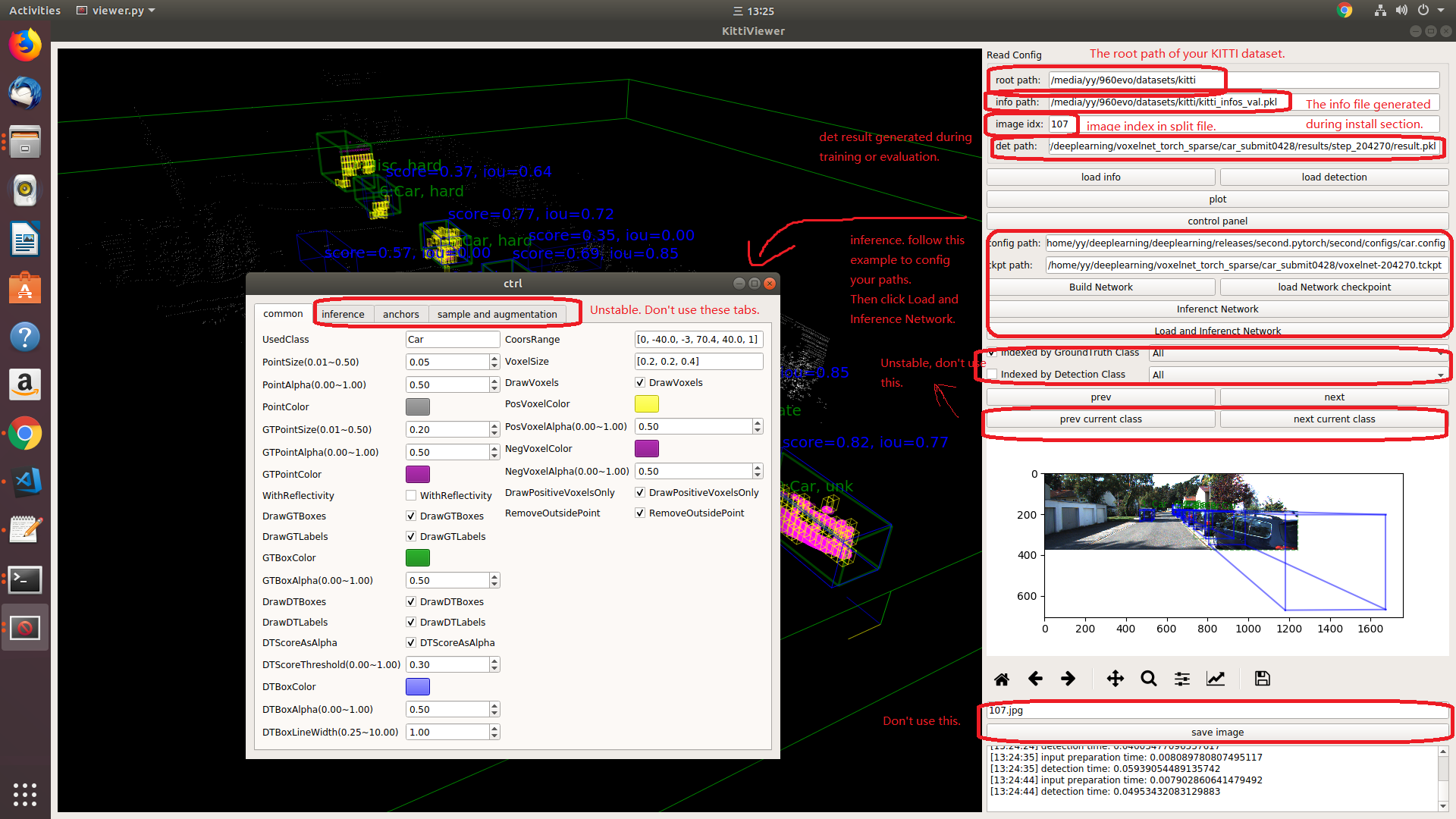 |
| 275 | + |
| 276 | +## Concepts |
| 277 | + |
| 278 | + |
| 279 | +* Kitti lidar box |
| 280 | + |
| 281 | +A kitti lidar box is consist of 7 elements: [x, y, z, w, l, h, rz], see figure. |
| 282 | + |
| 283 | +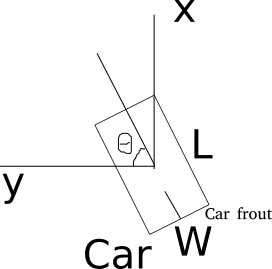 |
| 284 | + |
| 285 | +All training and inference code use kitti box format. So we need to convert other format to KITTI format before training. |
| 286 | + |
| 287 | +* Kitti camera box |
| 288 | + |
| 289 | +A kitti camera box is consist of 7 elements: [x, y, z, l, h, w, ry]. |
0 commit comments