The purpose of these packages (solutions expressed in Java and Spark) are to show how to implement basic machine learning algorithms (K-Means, Naive Bayes, Logistic Regression, Linear Regression, ...) in Spark and Spark's MLlib library. Spark's MLlib offers a suite of machine learning libraries for
- Naive Bayes
- Logistic Regression
- K-Means
- Linear Regression
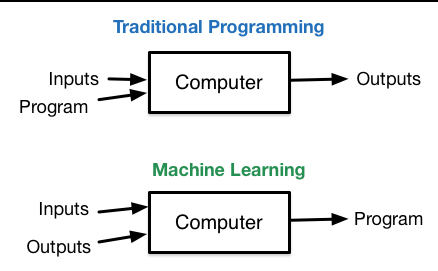
-
"Machine learning is a subfield of computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence. Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from example inputs in order to make data-driven predictions or decisions, rather than following strictly static program instructions." (source: https://en.wikipedia.org/wiki/Machine_learning)
-
"Machine learning is the science of getting computers to act without being explicitly programmed. In the past decade, machine learning has given us self-driving cars, practical speech recognition, effective web search, and a vastly improved understanding of the human genome. Machine learning is so pervasive today that you probably use it dozens of times a day without knowing it." (source https://www.coursera.org/learn/machine-learning)
-
The Elements of Statistical Learning, Data Mining, Inference, and Prediction, 2nd Edition
K-Means clustering is a clustering algorithm that can be used to partition your dataset into K (where K > 1) clusters. We now look at how we can implement K-Means clustering using Spark to cluster the featurized Wikipedia dataset. K-Means is one of the simplest un-supervised learning algorithms that solve the well known clustering problem.
For details on K-Means clustering, you should read
- A Tutorial on Clustering Algorithms
- K-means and Hierarchical Clustering
- K-Means: Step-By-Step Example
-
org.dataalgorithms.machinelearning.kmeans.Featurization
This is a standalone Spark program to featurize the WikiStats
-
org.dataalgorithms.machinelearning.kmeans.WikipediaKMeansUsingUtilVector
This solution implements K-Means algorithm using the org.apache.spark.util.Vector class
-
org.dataalgorithms.machinelearning.kmeans.WikipediaKMeansUsingMLlibVector
This solution implements K-Means algorithm using the org.apache.spark.mllib.linalg.Vector interface
Use simple logistic regression when you have one nominal variable and one measurement variable, and you want to know whether variation in the measurement variable causes variation in the nominal variable.
For details on Logistic Regression, you should read
- Logistic Regression
- A Tutorial on Logistic Regression
- Logistic Regression Tutorial
- Logit Models for Binary Data
- Introduction to Logistic Regression
These Spark programs detect breast cancer using Logistic Regression model
- org.dataalgorithms.machinelearning.logistic.BreastCancerDetectionBuildModel
The class BreastCancerDetectionBuildModel builds the model from the given training data
- org.dataalgorithms.machinelearning.logistic.BreastCancerDetection
This is the driver class, which uses the built model to classify new queried data
This solution detects spam and non-spam emails
- org.dataalgorithms.machinelearning.logistic.EmailSpamDetectionBuildModel
The class EmailSpamDetectionBuildModel builds the model from the given training data
- org.dataalgorithms.machinelearning.logistic.EmailSpamDetection
This is the driver class, which uses the built model to classify new queried data
"The Naive Bayes algorithm is an intuitive method that uses the probabilities of each attribute belonging to each class to make a prediction. It is the supervised learning approach you would come up with if you wanted to model a predictive modeling problem probabilistically. Naive Bayes simplifies the calculation of probabilities by assuming that the probability of each attribute belonging to a given class value is independent of all other attributes. This is a strong assumption but results in a fast and effective method." (source: http://machinelearningmastery.com/naive-bayes-classifier-scratch-python/)
Naive Bayes Classifier can be specified by using the following conditional probabilities:
P(a|b) = (P(b|a) P(a)) / P(b)
For details on Naive Bayes, you should read
The following Spark classes may be used to implement Naive Bayes:
-
org.apache.spark.mllib.classification.NaiveBayes Trains a Naive Bayes model given an RDD of (label, features) pairs.
-
org.apache.spark.mllib.classification.NaiveBayesModel Model for Naive Bayes Classifiers
Regression analysis is the art and science of fitting straight lines to patterns of data. Linear regression is a simple approach to supervised learning. It assumes that the dependence of Y on X1, X2, ..., Xn is linear. In reality, true regression functions are never linear.
For details on Linear Regression, you should read
-
Blog: Predicting Car Prices : Linear Regression http://www.datasciencecentral.com/profiles/blogs/predicting-car-prices-part-1-linear-regression
-
Training Data Set: https://github.com/datailluminations/PredictingToyotaPricesBlog/blob/master/ToyotaCorolla.csv
- View Mahmoud Parsian's profile on LinkedIn
- Please send me an email: [email protected]
- Twitter: @mahmoudparsian
Thank you!
best regards,
Mahmoud Parsian
