
English | 简体中文


YOLOv5🚀是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的公开研究,其中包含了在数千小时的研究和开发中所获得的经验和最佳实践。
请参阅YOLOv5 Docs,了解有关训练、测试和部署的完整文件。
安装
在Python>=3.7.0 的环境中克隆版本仓并安装 requirements.txt,包括PyTorch>=1.7。
git clone https://github.com/ultralytics/yolov5 # 克隆
cd yolov5
pip install -r requirements.txt # 安装推理
YOLOv5 PyTorch Hub 推理. 模型 自动从最新YOLOv5 版本下载。
import torch
# 模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# 图像
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# 推理
results = model(img)
# 结果
results.print() # or .show(), .save(), .crop(), .pandas(), etc.用 detect.py 进行推理
detect.py 在各种数据源上运行推理, 其会从最新的 YOLOv5 版本 中自动下载 模型 并将检测结果保存到 runs/detect 目录。
python detect.py --source 0 # 网络摄像头
img.jpg # 图像
vid.mp4 # 视频
path/ # 文件夹
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP 流训练
以下指令再现了 YOLOv5 COCO
数据集结果. 模型 和 数据集 自动从最新的YOLOv5 版本 中下载。YOLOv5n/s/m/l/x的训练时间在V100 GPU上是 1/2/4/6/8天(多GPU倍速). 尽可能使用最大的 --batch-size, 或通过 --batch-size -1 来实现 YOLOv5 自动批处理. 批量大小显示为 V100-16GB。
python train.py --data coco.yaml --cfg yolov5n.yaml --weights '' --batch-size 128
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
教程
- 训练自定义数据 🚀 推荐
- 获得最佳训练效果的技巧 ☘️ 推荐
- 使用 Weights & Biases 记录实验 🌟 新
- Roboflow:数据集、标签和主动学习 🌟 新
- 多GPU训练
- PyTorch Hub ⭐ 新
- TFLite, ONNX, CoreML, TensorRT 导出 🚀
- 测试时数据增强 (TTA)
- 模型集成
- 模型剪枝/稀疏性
- 超参数进化
- 带有冻结层的迁移学习 ⭐ 新
- 架构概要 ⭐ 新
使用经过我们验证的环境,几秒钟就可以开始。点击下面的每个图标了解详情。
| Deci ⭐ NEW | ClearML ⭐ NEW | Roboflow | Weights & Biases |
|---|---|---|---|
| Automatically compile and quantize YOLOv5 for better inference performance in one click at Deci | Automatically track, visualize and even remotely train YOLOv5 using ClearML (open-source!) | Label and export your custom datasets directly to YOLOv5 for training with Roboflow | Automatically track and visualize all your YOLOv5 training runs in the cloud with Weights & Biases |
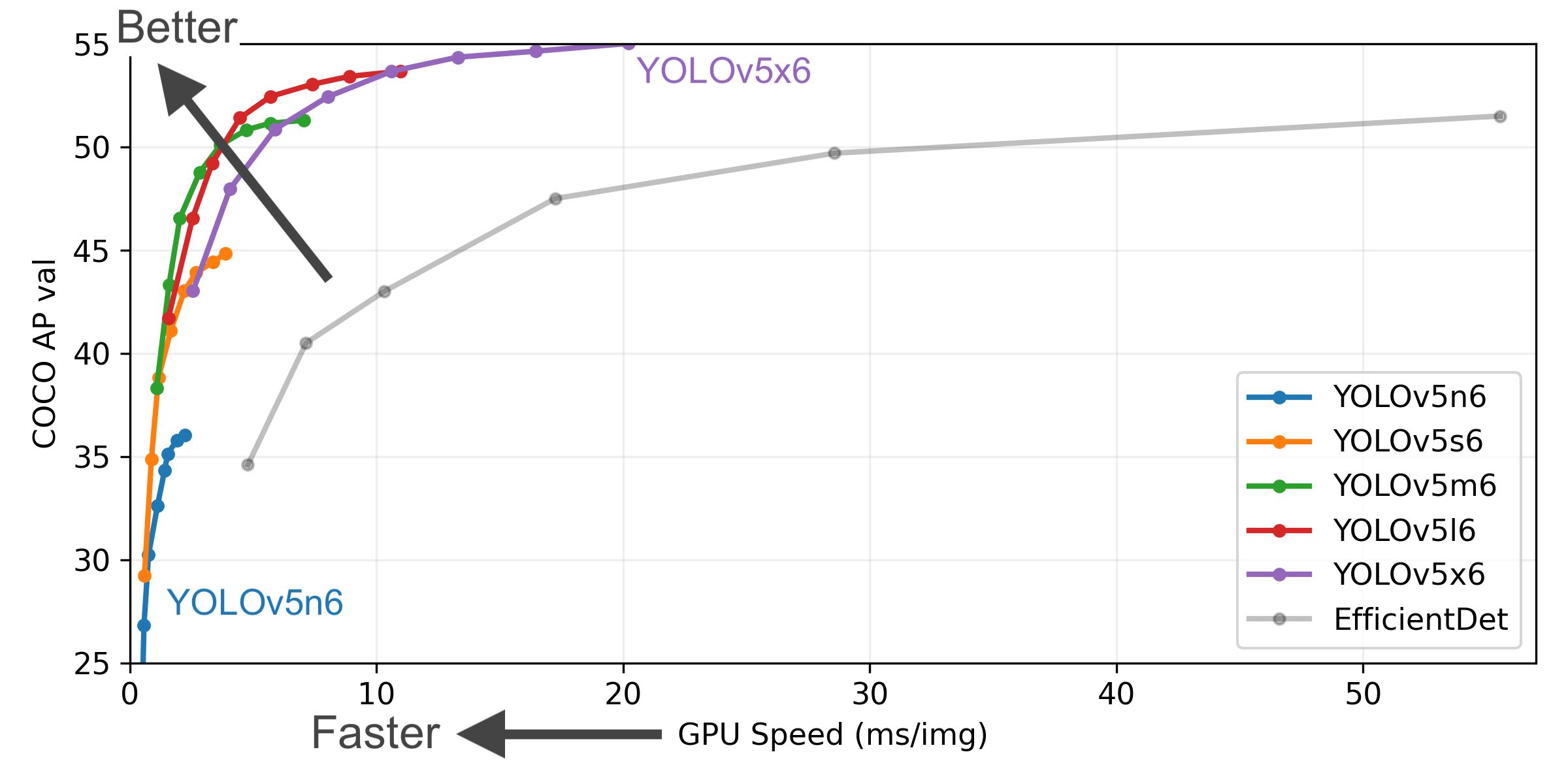
YOLOv5-P5 640 图像 (点击扩展)
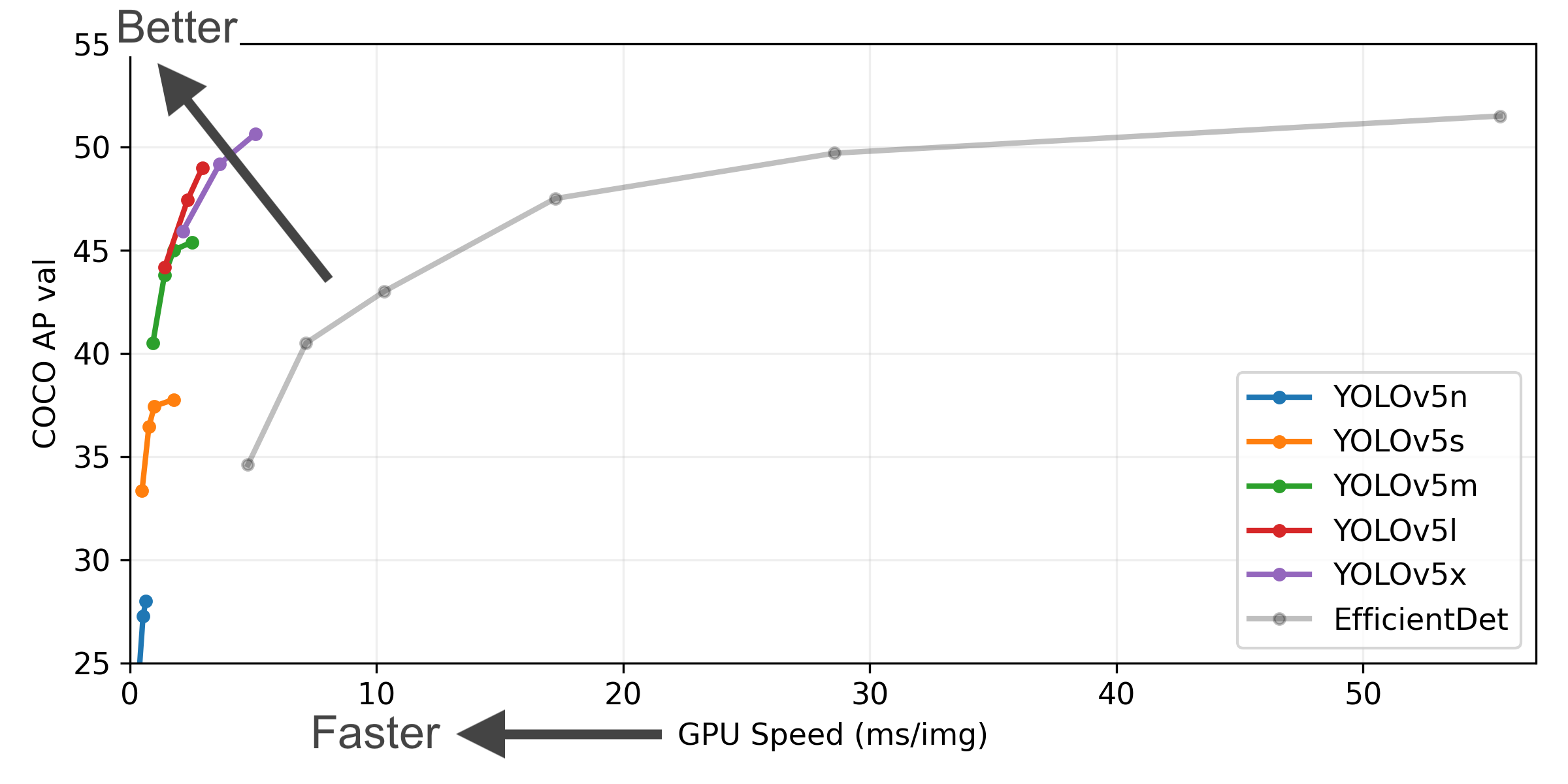
图片注释 (点击扩展)
- COCO AP val 表示 [email protected]:0.95 在5000张图像的COCO val2017数据集上,在256到1536的不同推理大小上测量的指标。
- GPU Speed 衡量的是在 COCO val2017 数据集上使用 AWS p3.2xlarge V100实例在批量大小为32时每张图像的平均推理时间。
- EfficientDet 数据来自 google/automl ,批量大小设置为 8。
- 复现 mAP 方法:
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
表格注释 (点击扩展)
- 所有检查点都以默认设置训练到300个时期. Nano和Small模型用 hyp.scratch-low.yaml hyps, 其他模型使用 hyp.scratch-high.yaml.
- mAPval 值是 COCO val2017 数据集上的单模型单尺度的值。
复现方法:python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - 使用 AWS p3.2xlarge 实例对COCO val图像的平均速度。不包括NMS时间(~1 ms/img)
复现方法:python val.py --data coco.yaml --img 640 --task speed --batch 1 - TTA 测试时数据增强 包括反射和比例增强.
复现方法:python val.py --data coco.yaml --img 1536 --iou 0.7 --augment
YOLOv5 release v6.2 brings support for classification model training, validation, prediction and export! We've made training classifier models super simple. Click below to get started.
Classification Checkpoints (click to expand)
We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro for easy reproducibility.
| Model | size (pixels) |
acc top1 |
acc top5 |
Training 90 epochs 4xA100 (hours) |
Speed ONNX CPU (ms) |
Speed TensorRT V100 (ms) |
params (M) |
FLOPs @224 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-cls | 224 | 64.6 | 85.4 | 7:59 | 3.3 | 0.5 | 2.5 | 0.5 |
| YOLOv5s-cls | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
| YOLOv5m-cls | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
| YOLOv5l-cls | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
| YOLOv5x-cls | 224 | 79.0 | 94.4 | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
| ResNet18 | 224 | 70.3 | 89.5 | 6:47 | 11.2 | 0.5 | 11.7 | 3.7 |
| ResNet34 | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
| ResNet50 | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
| ResNet101 | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
| EfficientNet_b0 | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
| EfficientNet_b1 | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
| EfficientNet_b2 | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
| EfficientNet_b3 | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
Table Notes (click to expand)
- All checkpoints are trained to 90 epochs with SGD optimizer with lr0=0.001 at image size 224 and all default settings. Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2.
- Accuracy values are for single-model single-scale on ImageNet-1k dataset.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 - Speed averaged over 100 inference images using a Google Colab Pro V100 High-RAM instance.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 --batch 1 - Export to ONNX at FP32 and TensorRT at FP16 done with
export.py.
Reproduce bypython export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224
Classification Usage Examples (click to expand)
YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the --data argument. To start training on MNIST for example use --data mnist.
# Single-GPU
python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
# Multi-GPU DDP
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3Validate accuracy on a pretrained model. To validate YOLOv5s-cls accuracy on ImageNet.
bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
python classify/val.py --weights yolov5s-cls.pt --data ../datasets/imagenet --img 224Run a classification prediction on an image.
python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpgmodel = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-cls.pt') # load from PyTorch HubExport a group of trained YOLOv5-cls, ResNet and EfficientNet models to ONNX and TensorRT.
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224我们重视您的意见! 我们希望给大家提供尽可能的简单和透明的方式对 YOLOv5 做出贡献。开始之前请先点击并查看我们的 贡献指南,填写YOLOv5调查问卷 来向我们发送您的经验反馈。真诚感谢我们所有的贡献者!

关于YOLOv5的漏洞和功能问题,请访问 GitHub Issues。商业咨询或技术支持服务请访问https://ultralytics.com/contact。