Code for the paper The CoSTAR Block Stacking Dataset: Learning with Workspace Constraints, implementing HyperTrees.
Author and maintainer: Andrew Hundt <[email protected]>
Cite
@article{hundt2019costar,
title={The CoSTAR Block Stacking Dataset: Learning with Workspace Constraints},
author={Andrew Hundt and Varun Jain and Chia-Hung Lin and Chris Paxton and Gregory D. Hager},
journal = {Intelligent Robots and Systems (IROS), 2019 IEEE International Conference on},
year = 2019,
url = {https://arxiv.org/abs/1810.11714}
}
Code using this dataset is also available at costar_dataset and rENAS: Regression Efficient Neural Architecture Search.
These instructions are with minimal dependencies where you'll be training & predicting on the datasets.
# make sure your python2 is up to date. python3 probably works but is not tested
python2 -m pip install --upgrade 2 setuptools wheel --user
# create the installation directory
mkdir -p ~/src
cd ~/src
# install the custom keras-contrib version with specific costar_plan APIs
git clone https://github.com/ahundt/keras-contrib -b costar_plan
cd keras-contrib
python2 -m pip install -e . --user --upgrade
# install costar_hyper and its dependencies
cd ~/src
git clone https://github.com/cpaxton/costar_plan
cd costar_plan
# this will run the costar_hyper setup
python2 -m pip install -e . --user --upgrade
Setup of the larger costar_plan code base is run separately via the ros catkin package.
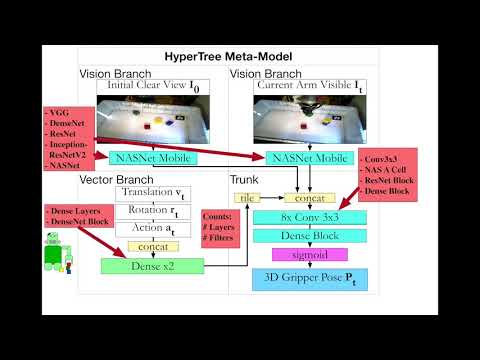
The block stacking dataset has a robot attempting to stack 3 colored blocks, as described in Training Frankenstein's Creature To Stack: HyperTree Architecture Search. First check out the CoSTAR Block Stacking Dataset Website to get an idea of how everything works.

We highly recommend looking at the CoSTAR Block Stacking Dataset Website and download instructions.
Six lines to read one file from the dataset (60MB example success file download link):
import h5py
filename = '2018-05-23-18-00-08_example000001.success.h5f'
h5 = h5py.File(filename, 'r')
joint_angle_key = 'q'
joint_angles = np.array(h5[joint_angle_key])
print(joint_angles)Detailed documentation is on the costar dataset website 'Using the Dataset' section and in the dataset README.md.
More detailed example of viewing data:
#!/usr/bin/env python
import sys
filename = sys.argv[1]
import h5py
import matplotlib.pyplot as plt
import numpy as np
from image import *
horizon = 10
i0 = 0
h5 = h5py.File(filename, 'r')
string = list(h5["label_to_string"])
label = np.array(h5["label"])
imgs = ConvertPNGListToNumpy(np.array(h5["images_rgb"]))
changed = np.abs(np.diff(label, axis=-1)) > 0
selected = np.zeros_like(label)
selected[1:] = changed
selected[-1] = 1
selected[0] = 1
selected = selected > 0
selected_action = np.zeros_like(label)
selected_action[:-1] = changed
selected_action[-1] = 1
selected_action[0] = 1
selected_action = selected_action > 0
print(selected)
selected_imgs = imgs[selected]
plt.figure()
for i, img in enumerate(selected_imgs):
plt.subplot(1,len(selected_imgs),i+1)
plt.axis("off")
plt.imshow(img)
plt.figure()
plt.axis("off")
plt.imshow(selected_imgs[4])
plt.show()some of those fields will vary for different use cases.
Costar Block Stacking Dataset (download instructions)
Configure hypertree_hyperopt.py to run on the problem you'd like, the script supports both the Cornell and the costar block stacking dataset.
Options for problem types include semantic_grasp_regression, semantic_translation_regression, semantic_rotation_regression. Uncomment the the settings in the file for the preferred problem type. Once you have edited the file for your use case, run the following command:
while true; do export CUDA_VISIBLE_DEVICES="0" && export TF_CPP_MIN_LOG_LEVEL="3" && python2 hypertree_hyperopt.py --data_dir "~/.keras/datasets/costar_block_stacking_dataset_v0.4/blocks_only/"; done
By default, this will run the hyperopt search on a loop with 100 random models and 10 Bayesian models each run until you stop it with ctrl + c. These limits are set due to an memory leak in the block stacking hdf5 reading code which has not yet been resolved. They can be modified in hypertree_hyperopt.py by changing initial_num_samples for the number of random models and maximum_hyperopt_steps for the number of Bayesian models. If you run out of memory, lower these numbers. Your GPU should have at least 7GB memory, but preferably 10-12GB of memory.
After running hyperopt, you will have collected a dataset of folders with results for each model; collate the results as follows:
python hyperopt_rank.py --log_dir hyperopt_logs_costar_block_stacking_train_ranked_regression --sort_by val_grasp_acc --ascending=False --nofilter_epoch --filter_unique && csvtotable hyperopt_logs_costar_block_stacking_train_ranked_regression/hyperopt_rank.csv hyperopt_logs_costar_block_stacking_train_ranked_regression/hyperopt_rank.html -o
Here is an alternate ranking command that you can just leave up:
while true; do python hyperopt_rank.py --log_dir 2018_10_hyperopt_logs_costar_grasp_regression --sort_by="val_cart_error" --ascending=True --nofilter_epoch --filter_unique && csvtotable 2018_10_hyperopt_logs_costar_grasp_regression/hyperopt_rank.csv 2018_10_hyperopt_logs_costar_grasp_regression/hyperopt_rank.html -o; sleep 1200; done
hyperopt_rank.py produces a file hyperopt_rank.csv with all of the best models sorted by the chosen metric, in the above case val_grasp_acc. Available metrics can be viewed in the file with column prefix val_.
The filter_unique flag eliminates files with the same basename column in the .csv to avoid training on the same model multiple times.
csvtotable is used to convert the csv files to html for easy viewing on a remote machine. You can also simply open the csv file in openoffice, google sheets, excel, etc, or the html file in a web browser.
Next, directly edit costar_block_stacking_train_ranked_regression.py to configure a run through the top ranked models. Note that you have to match problem_type and change FLAGS.epochs. Modify the file to run perhaps 30 epochs to see which ones perform best with more training. costar_block_stacking_train_ranked_regression.py will load the hyperopt_rank.csv file, sort it again based on the chosen configuration, then train each model for the specified number of epochs:
export CUDA_VISIBLE_DEVICES="0" && python2 costar_block_stacking_train_ranked_regression.py --log_dir hyperopt_logs_costar_block_stacking_train_ranked_regression --run_name 30_epoch
Re-run the hyperopt_rank.py command above to update the model rankings with the new data. Do a final run on the absolute best models for 300 epochs, again editing the file for the new number of epochs:
export CUDA_VISIBLE_DEVICES="0" && python2 costar_block_stacking_train_ranked_regression.py --log_dir hyperopt_logs_costar_block_stacking_train_ranked_regression --run_name 300_epoch
You may wish to use the --learning_rate_schedule triangular flag for one run and then the --learning_rate_schedule triangular2 --load_weights path/to/previous_best_weights.h5 for a second run. These learning rate schedules use the keras_contrib cyclical learning rate callback, see Cyclical learning rate repo for a detailed description and paper links.
cd 2018_10_hyperopt_logs_costar_grasp_regression/..
python -m SimpleHTTPServer 4004
now browse to localhost:4004 and you can look at the html file generated by the csvtotable command further up.

Plot results with hyperopt_plot.py.
curl http://localhost:4004/2018_10_hyperopt_logs_costar_grasp_regression/hyperopt_rank.csv --output ~/Downloads/hyperopt_rank.csv && bokeh serve --show hyperopt_plot.py --args --rank_csv ~/Downloads/hyperopt_rank.csv --problem_type semantic_translation_regression
This should open your web browser with a plot similar to the one above. A file hyperopt_plot.csv will also be generated which you can load with your favorite utility.
These are instructions for training on the cornell grasping dataset.
To download the dataset and generate the tensorflow tfrecord dataset files simply run the following command:
python cornell_grasp_dataset_writer.py
This should take about 5-6 GB of space, and by default the dataset files will go in:
flags.DEFINE_string('data_dir',
os.path.join(os.path.expanduser("~"),
'.keras', 'datasets', 'cornell_grasping'),
"""Path to dataset in TFRecord format
(aka Example protobufs) and feature csv files.""")
Check the value of the following parameter with each command:
--log_dir
Files will be created containing training results in that file.
By default it is ./logs_cornell/:
Regression tries to predict a grasp position and orientation based on an image alone.
export CUDA_VISIBLE_DEVICES="0" && python cornell_grasp_train_regression.py --pipeline_stage k_fold --run_name 60_epoch_real_run
The following commands will generate a hyperopt summary.
Generating a hyperparameter search results summary for cornell regression
python hyperopt_rank.py --log_dir hyperopt_logs_cornell_regression --sort_by val_grasp_jaccard
Please note that there are currently bugs in the loss with the regression problem. Additonally, a custom command must be run to find the correct intersection over union score.
Takes a grasp position, orientation, gripper width, etc as input, then returns a score indicating if it will be a successful grasp of an object or a failed grasp. Given the grasp command input, the proposed grasp image is rotated and centered on the grasp, so that all grasps have the gripper in a left-right orientation to the image and the gripper is at the center.
hypertree_hyperopt.pyis basically a configuration file used to configure hyperparameter optimization for the cornell grasping dataset.hyperopt.pyis another configuration file that sets up the range of models you should search during hyperopt.- shared by google and cornell for both classification and regression training
- you may also want to modify this to change what kind of models are being searched.
In hypertree_hyperopt.py make sure the following variable is set correctly:
FLAGS.problem_type = 'classification'
This will run hyperopt search for a couple of days on a GTX 1080 or Titan X to find the best model.
Hyperparameter search to find the best model:
export CUDA_VISIBLE_DEVICES="0" && python hypertree_hyperopt.py --log_dir hyperopt_logs_cornell_classification
Result will be in files with names like these:
2018-05-08-17-55-00__bayesian_optimization_convergence_plot.png
2018-05-08-17-55-00__hyperoptions.json
2018-05-08-17-55-00__optimized_hyperparams.json
2018-05-23-19-08-31__hyperoptions.json
Generating a hyperparameter search results summary for cornell classification:
python hyperopt_rank.py --log_dir hyperopt_logs_cornell_classification --sort_by val_binary_accuracy
This will generate a hyperopt ranking file:
hyperopt_rank.csv
Look at the CSV file above, and it will have different model configurations listed as well as how well each performed. Select the best performing model, typically the top entry of the list, and look for the json filename in that row which stores the best configuration. With this file, we need to run k-fold cross validation to determine how well the model actually performs.
Perform K-fold cross validation on the model for a more robust comparison of your model against other papers and models:
cornell_grasp_train_classification.pyconfiguration file to train a single classification model completely.- Can do train/test/val splits
- Can do k-fold cross validation
- Be sure to manually edit the file with the json file specifying the hyperparameters for the model you wish to load, number of epochs, etc.
Here is one example configuration:
FLAGS.load_hyperparams = ('hyperparams/classification/2018-05-03-17-02-01_inception_resnet_v2_classifier_model-'
'_img_inception_resnet_v2_vec_dense_trunk_vgg_conv_block-dataset_cornell_grasping-grasp_success_hyperparams.json')
Here is the command to actually run k-fold training:
export CUDA_VISIBLE_DEVICES="0" && python cornell_grasp_train_classification.py --run_name 2018-04-08-21-04-19_s2c2hw4 --pipeline_stage k_fold
After it finishes running there should be a file created named *summary.json with your final results.
Note: The Google Brain Grasping Dataset has several important limitations which must be considered before trying it out:
- There is no validation or test dataset with novel objects
- There is no robot model available, and the robot is not commercially available
- Data is collected at 1Hz and may not be well synchronized w.r.t. time.
- The robot may move vast distances and change directions completely between frames.

Plus now there is a flag to draw a circle at the location of the gripper as stored in the dataset:

A new feature is writing out depth image gifs:

Image data can be resized:

The blue circle is a visualization, not actual input, which marks the gripper stored in the dataset pose information. You can see the time synchronization issue in these frames.
Color augmentation is also available:


- copy the .ttt file and the .so file (.dylib on mac) into the
costar_google_brainrobotdata/vrepfolder. - Run vrep with -s file pointing to the example:
./vrep.sh -s ~/src/costar_ws/src/costar_plan/costar_google_brainrobotdata/vrep/kukaRemoteApiCommandServerExample.ttt
- vrep should load and start the simulation
- make sure the folder holding
vrep_grasp.pyis on your PYTHONPATH - cd to
~/src/costar_ws/src/costar_plan/costar_google_brainrobotdata/, or wherever you put the repository - run
export CUDA_VISIBLE_DEVICES="" && python2 vrep_grasp.py
To run the search execute the following command
export CUDA_VISIBLE_DEVICES="0" && python2 google_grasp_hyperopt.py --run_name single_prediction_all_transforms
Generating a hyperparameter search results summary for google brain grasping dataset classification:
python hyperopt_rank.py --log_dir hyperopt_logs_google_brain_classification --sort_by val_acc
Training Frankenstein's Creature To Stack: HyperTree Architecture Search