The goals / steps of this project are the following:
- Use the simulator provided by Udacity to collect data of good driving behavior
- Preprocess the data before training
- Build a convolutional neural network using Keras that predicts steering angles from driving images
- Train and validate the model
- Test that the model successfully drives around a test track without leaving the road
My project includes the following files:
- model.ipynb containing the code to create and train the model
- model.py contains the code from model.ipynb without any of the illustrations or visualizations
- drive.py for driving the car in autonomous mode
- model.h5 containing a trained convolution neural network
- Writeup.md which contains a through documentation of my work
- Anaconda 4.2 for Python 3.5
- Keras
- TensorFlow
- OpenCV
I collected data by driving around the first track multiple times to collect images of certain behaviors:
- Good-Driving Behavior (2 laps in each direction)
- Recovery Driving (1 lap)
Recovery Driving constitutes driving to the edge of each lane and recording myself driving back to the center. I did this for both sides.
Collected data:
- View from 3 different cameras
- Steering angle
All the data was stored in the data directory.
There are 3 images for any given steering angle. But, the steering angle from each angle is very different. There is an offset to add or subtract based on the camera(add for left, subtract for right). This presents itself as another hyperparameter to play around with during training.
To increase the size of the dataset, I decided to create fliped versions of all images and negated their steering. This doubles the size of the dataset, and proved really useful in making the model generalize better.
I also cropped all images to make the model focus only on the road and not the sky. I got the idea for it from the Udacity lectures and the Nvidia paper(shown below).
At first, I tried to base my model on the model used by the GoogLenet Team. Their model claimed to speedup training by 3-10 times. They did this by makign use of Inception modules.
Unfortunately, their model was 22 layers deep. I was able to build the model, but it was far too big to run on a single 4GB GPU on AWS. I did not realize this right away. It took a few days of playing around and experimenting to figure out the cause of the problem. But, eventually, I realized that there were far too many layers and far too many variables to train with a single GPU.
So, I decided to base my model on the model used by Nvidia instead.
I later realized that I may still be able to use the GoogLenet structure I created with a generator. But, it was far too complicated a structure and would take too long to setup and run, and I had already gotten the Nvidia structure working.

The Nvidia Model in Keras:
- Convolution2D(24, 5, 5, border_mode='same', subsample=(2, 2))
- Convolution2D(36, 5, 5, border_mode='same', subsample=(2, 2))
- Convolution2D(48, 5, 5, border_mode='same', subsample=(2, 2))
- Convolution2D(64, 3, 3, border_mode='same', subsample=(2, 2))
- Convolution2D(64, 3, 3, border_mode='same', subsample=(2, 2))
- Flatten()
- Dense(1000)
- Dense(100)
- Dense(50)
- Dense(10)
- Dense(1)
This model makes use of 5 Convolutions with 5x5 filters with strides of 2 for the first 5 steps. Afterwards, you have 5 fully-connected layers, ending with a single output for steering.
I used Adam Optimizer and Mean-Squared Error.
Check out this Link. It gives a really good comparison of optimization functions and why Adam is a good choice. I used the default learning rate of .001.
Mean-Squared Error is a very standard cost function when working with numerical values. Especially when you are trying to predict them. As the output for this model was not categorical, it made sense to use this function.
When I ran the model as is, I did not perform that well with my validation-loss. It was, unfortunately, very high. So, I decided to start by adding an activation function. I decided to go with RELU, since it is generally a good starting place in terms of activation functions. Validation error dropped, but it did not drop enough to be useful or signal that the model was performing well.
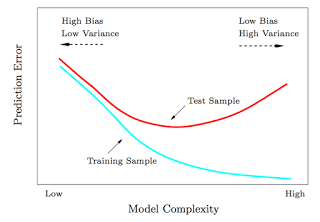
I had a serious issue with variance. The loss on the training set was dropping steadily, but the loss of the validation-set was ever increasing. In other words, I was underfitting, badly.
So, my next step was to normalize the images. I started with: Lambda(lambda x: (x / 255) - 0.5)). This was the function provided by Udacity. However, I noticed that my other classmates had found better success by using Lambda(lambda x: (x / 127.5 - 1.0)). So, I followed their lead and used the function instead. It improved performance, but I was still underfitting.
It was at this time, that I decided to go over my code to see if there were any bugs I had inadvertantly overlooked. And then, I found them.
- My generator was only putting one image in the validation set. Which explains why my validation-loss was so high and climbing.
- I had been training my model on images that were cropped in the generator that provided the training-set batches. So, when I tried to make predictions with full-size images, the program would crash.
- The first problem was easily fixed by fixing the bug which only added one image.
- I decided to remove the cropping function from the generator. Instead, I added a cropping layer to the model. I placed it right above the Normalization layer. This way, I was not normalizing values that I was getting rid of anyways.
After this issue was solved, my model began to perform a lot better. But this time, I had a new problem. I was in grave danger of over-fitting. The solution to this was very simple, add a Dropout Layer after each Convolutional Layer.
From this point forward, I was experimenting with dropout percentages and combinations of percentages. I started with 0.5. But I slowly worked my way down to 0.3 and 0.4 for my different Dropout Layers.
The last hyperparameter to play with was the steering angle offset. I started with 0.2. But after changing it to 0.21, I noticed that steering was a lot better, so I just stopped there.
- Cropping2D(cropping=((50,20), (0,0)), input_shape=(160,320,3))
- Lambda(lambda x: (x / 127.5 - 1.0))
- Convolution2D(24, 5, 5, border_mode='same', activation = 'relu', subsample=(2, 2))
- Dropout(0.4)
- Convolution2D(36, 5, 5, border_mode='same', activation = 'relu', subsample=(2, 2))
- Dropout(0.3)
- Convolution2D(48, 5, 5, border_mode='same', activation = 'relu', subsample=(2, 2))
- Dropout(0.3)
- Convolution2D(64, 3, 3, border_mode='same', activation = 'relu', subsample=(2, 2))
- Dropout(0.3)
- Convolution2D(64, 3, 3, border_mode='same', activation = 'relu', subsample=(2, 2))
- Dropout(0.3)
- Flatten()
- Dense(1000)
- Dense(100)
- Dense(50)
- Dense(10)
- Dense(1)
The saved model that I used to record autonomous driving is stored in model.h5. The validation-loss for this model was 0.0287. Before this, I tried to record the car running with on a model.h5 file with a validation-loss of 0.0339. The car drove well, but it had to recover back to the center of the road twice on curves. So, I re-ran the model for another 10 epochs and got my final validation-loss. This time, the car drove without any issues or recovery. That .5% made a huge difference.
The vehicle is able to drive autonomously around the track without leaving the road or having to recover.

Out of curiousity, I ran the model for another 10 epochs and got a final validation-loss of 0.0269, and saved the model in model2.h5.