diff --git a/README.md b/README.md
index a8dbb55..250ac3d 100644
--- a/README.md
+++ b/README.md
@@ -932,7 +932,7 @@ each iteration, each specified variable in the dataset is imputed using
the other variables in the dataset. These iterations should be run until
it appears that convergence has been met.
-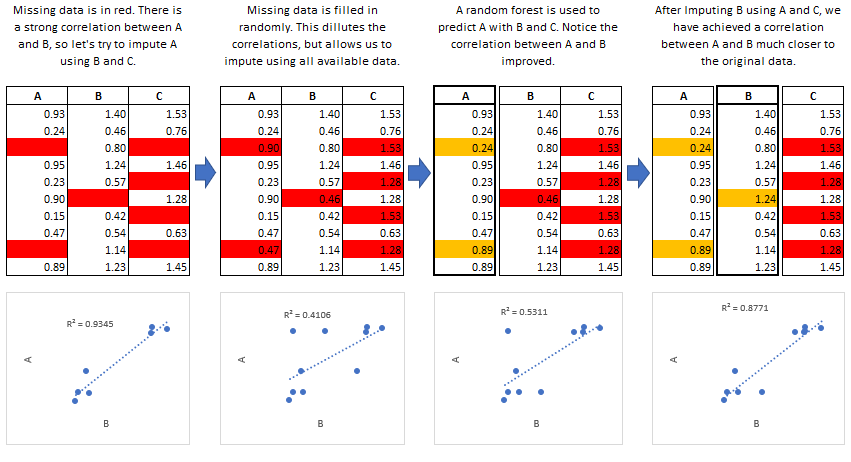 +
+ This process is continued until all specified variables have been
imputed. Additional iterations can be run if it appears that the average
@@ -984,7 +984,7 @@ are selected, from which a value is chosen at random. This can be
specified on a column-by-column basis. Going into more detail from our
example above, we see how this works in practice:
-
This process is continued until all specified variables have been
imputed. Additional iterations can be run if it appears that the average
@@ -984,7 +984,7 @@ are selected, from which a value is chosen at random. This can be
specified on a column-by-column basis. Going into more detail from our
example above, we see how this works in practice:
- +
+ This method is very useful if you have a variable which needs imputing
which has any of the following characteristics:
diff --git a/README_gen.ipynb b/README_gen.ipynb
index 0734c40..8ded140 100644
--- a/README_gen.ipynb
+++ b/README_gen.ipynb
@@ -1281,7 +1281,7 @@
"the other variables in the dataset. These iterations should be run until\n",
"it appears that convergence has been met.\n",
"\n",
- "
This method is very useful if you have a variable which needs imputing
which has any of the following characteristics:
diff --git a/README_gen.ipynb b/README_gen.ipynb
index 0734c40..8ded140 100644
--- a/README_gen.ipynb
+++ b/README_gen.ipynb
@@ -1281,7 +1281,7 @@
"the other variables in the dataset. These iterations should be run until\n",
"it appears that convergence has been met.\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"This process is continued until all specified variables have been\n",
"imputed. Additional iterations can be run if it appears that the average\n",
@@ -1337,7 +1337,7 @@
"specified on a column-by-column basis. Going into more detail from our\n",
"example above, we see how this works in practice:\n",
"\n",
- "
\n",
"\n",
"This process is continued until all specified variables have been\n",
"imputed. Additional iterations can be run if it appears that the average\n",
@@ -1337,7 +1337,7 @@
"specified on a column-by-column basis. Going into more detail from our\n",
"example above, we see how this works in practice:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"This method is very useful if you have a variable which needs imputing\n",
"which has any of the following characteristics:\n",
diff --git a/docs/index.rst b/docs/index.rst
index 04473d3..1007dcb 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -10,9 +10,36 @@ This documentation is meant to describe class methods and parameters only,
for a thorough walkthrough of usage, please see the
`Github README `_.
+In general, the user will only be interacting with these two classes:
-Fast, memory efficient Multiple Imputation by Chained Equations (MICE)
-with lightgbm. The R version of this package may be found
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Classes:
+
+ ImputationKernel
+ ImputedData
+
+
+How miceforest Works
+--------------------
+
+Multiple Imputation by Chained Equations ‘fills in’ (imputes) missing
+data in a dataset through an iterative series of predictive models. In
+each iteration, each specified variable in the dataset is imputed using
+the other variables in the dataset. These iterations should be run until
+it appears that convergence has been met.
+
+.. image:: https://i.imgur.com/2L403kU.png
+ :target: https://github.com/AnotherSamWilson/miceforest?tab=readme-ov-file#the-mice-algorithm
+
+This process is continued until all specified variables have been
+imputed. Additional iterations can be run if it appears that the average
+imputed values have not converged, although no more than 5 iterations
+are usually necessary.
+
+This package provides fast, memory efficient Multiple Imputation by Chained
+Equations (MICE) with lightgbm. The R version of this package may be found
`here `_.
`miceforest` was designed to be:
@@ -30,13 +57,4 @@ with lightgbm. The R version of this package may be found
- Can impute new, unseen datasets quickly
- Kernels are efficiently compressed during saving and loading
- Data can be imputed in place to save memory
- - Can build models on non-missing data
-
-
-
-.. toctree::
- :maxdepth: 1
- :caption: Contents:
-
- ImputationKernel
- ImputedData
+ - Can build models on non-missing data
\ No newline at end of file
\n",
"\n",
"This method is very useful if you have a variable which needs imputing\n",
"which has any of the following characteristics:\n",
diff --git a/docs/index.rst b/docs/index.rst
index 04473d3..1007dcb 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -10,9 +10,36 @@ This documentation is meant to describe class methods and parameters only,
for a thorough walkthrough of usage, please see the
`Github README `_.
+In general, the user will only be interacting with these two classes:
-Fast, memory efficient Multiple Imputation by Chained Equations (MICE)
-with lightgbm. The R version of this package may be found
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Classes:
+
+ ImputationKernel
+ ImputedData
+
+
+How miceforest Works
+--------------------
+
+Multiple Imputation by Chained Equations ‘fills in’ (imputes) missing
+data in a dataset through an iterative series of predictive models. In
+each iteration, each specified variable in the dataset is imputed using
+the other variables in the dataset. These iterations should be run until
+it appears that convergence has been met.
+
+.. image:: https://i.imgur.com/2L403kU.png
+ :target: https://github.com/AnotherSamWilson/miceforest?tab=readme-ov-file#the-mice-algorithm
+
+This process is continued until all specified variables have been
+imputed. Additional iterations can be run if it appears that the average
+imputed values have not converged, although no more than 5 iterations
+are usually necessary.
+
+This package provides fast, memory efficient Multiple Imputation by Chained
+Equations (MICE) with lightgbm. The R version of this package may be found
`here `_.
`miceforest` was designed to be:
@@ -30,13 +57,4 @@ with lightgbm. The R version of this package may be found
- Can impute new, unseen datasets quickly
- Kernels are efficiently compressed during saving and loading
- Data can be imputed in place to save memory
- - Can build models on non-missing data
-
-
-
-.. toctree::
- :maxdepth: 1
- :caption: Contents:
-
- ImputationKernel
- ImputedData
+ - Can build models on non-missing data
\ No newline at end of file